ゼロからのCOM - COMの目的とその仕組み
いちごパック >
COM/ActiveXの解説 >
ゼロからのCOM - COMの目的とその仕組み
COMとは何か?
ソフトウェアには様々なプログラミング言語、技術、プログラミングテクニックが使われています。 便利で高機能なソフトウェアの多くは、これらの組み合わせで成り立っています。 COM(Component Object Model)とは、 システムとしてこれらをWindowsプログラマに提供するためのプログラミングツールです。COMは大雑把にいえば、次の機能を持つプログラミングツールです。
C++言語ではCOMのすべての機能を利用できますが、 言語によってはその利用が一部の機能に限定されるため、 互換性を考慮したプログラミングが必要になることもあります。
インターフェースとオブジェクト
COMシステムは、ライブラリ(COMサーバ)のオブジェクトを、 呼び出し側(COMクライアント)から呼び出すための機能を提供します。 COMシステムでは、次のような形で呼び出しが実現されています。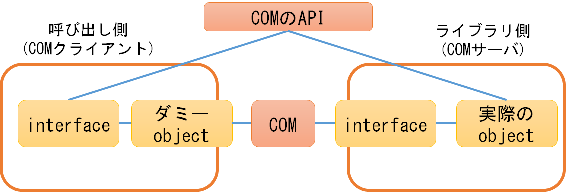 C++言語を利用する場合、COMはC++のclassを利用したオブジェクト指向のプログラミングコードとして実装できます。
COMとC++言語の対応は次のようになります。
C++言語を利用する場合、COMはC++のclassを利用したオブジェクト指向のプログラミングコードとして実装できます。
COMとC++言語の対応は次のようになります。
| COM | C++言語 |
| インターフェース | 純粋仮想関数のみのインターフェースクラス |
| オブジェクト | インターフェースクラスを継承し、それを実装したクラス |
| 確保 | CoCreateInstance |
| 解放 | すべてのオブジェクトが持つRelease()メソッド |
すべてのオブジェクトはRelease()メソッドのほかに、AddRef()メソッドとQueryInterface()メソッドを持ちます。 AddRef()メソッドはオブジェクトの参照カウントを1増やすメソッドです。
QueryInterface()メソッドは、多重継承など、オブジェクトが複数のインターフェースを実装している場合に、 オブジェクトが備える他のインターフェースを取得するために利用できます。 インターフェースを取得した場合、そのポインタを返すために参照カウントが1増やされています。
COMとシステム
COMではシステム全体の情報をレジストリで管理し、 プロセス固有の情報はApartmentと呼ばれるグループ単位で管理しています。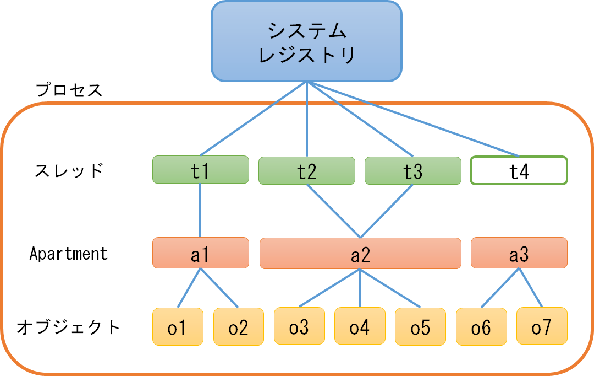 COMはスレッド単位で初期化でき、
初期化されたスレッドはApartmentに所属させることができます。
COMが管理するオブジェクトは、オブジェクト作成時にスレッドが所属するApartmentに所属します。
COMはスレッド単位で初期化でき、
初期化されたスレッドはApartmentに所属させることができます。
COMが管理するオブジェクトは、オブジェクト作成時にスレッドが所属するApartmentに所属します。
スレッドやオブジェクトを複数のApartmentに所属させることはできません。 Apartmentに所属していないスレッドは、COMが管理するオブジェクトを作成できません。
スレッド、Apartment、オブジェクトのルールをまとめると次のようになります。
| Apartment | 0〜複数のスレッド、0〜複数のオブジェクトを所有できる。 |
| スレッド | 0〜1つのApartmentに所属できる。 |
| オブジェクト | 1つのApartmentに必ず所属する。 |
GUID
各プログラマが自由にクラス名やインターフェース名を与えると、 同じ名前を使ってしまうことがあります。 この対策としてCOMでは、 クラス名やインターフェース名に128ビットの数値を割りあてて、 システムがクラス名やインターフェース名を識別する際に128ビットの数値を用います。クラス名やインターフェース名の識別に用いる128ビットの数値をGUID(Globally Unique Identifier)といいます。 クラス名を識別するIDはCLSID、インターフェース名を識別するIDはIIDと呼ばれます。 また、GUIDはUUID(Universally Unique Identifier)と呼ばれることもあります。
GUIDの生成には、Visual Studioに付属しているguidgenか、 guidgenのコマンドライン版であるuuidgenというプログラムを利用します。 これらのプログラムはイーサネットアドレス等を利用して、 他の環境で生成されたGUIDも含めて一意となるような128ビットの数値を生成してくれます。
C++のプログラミングではGUIDは構造体として扱われます。 説明のために構造体の要素には仮の名前を与えましたが、要素には直接アクセスできないと考えてください。
typedef struct {
unsigned long __data32;
unsigned short __data16_1;
unsigned short __data16_2;
unsigned char __data8[8];
} GUID;
typdef GUID UUID;
typdef GUID IID;
typdef GUID CLSID;
#define REFGUID const GUID &
#define REFIID REFGUID
#define REFCLSID REFGUID
構造体はそのままでは比較できませんが、 これについてはIDが等しいかを調べる関数が用意されています。
inline bool operator==( REFGUID id1, REFGUID id2 )
{
return 0 == memcmp( &id1, &id2, sizeof(GUID) );
}
inline bool operator!=( REFGUID id1, REFGUID id2 )
{
return 0 != memcmp( &id1, &id2, sizeof(GUID) );
}
extern const CLSID CLSID_Ichigo1;
const CLSID CLSID_Ichigo1 =
{ 0x227a0711, 0xd089, 0x42aa, { 0x84, 0x28, 0x52, 0xdd, 0x48, 0xa1, 0x41, 0x39 } };
Windowsでは、extern定義とcppでの実装の両方をまとめて1つのコードで表現するために、 DEFINE_GUIDというマクロを用意しています。DEFINE_GUIDマクロは次のように使います。
DEFINE_GUID(CLSID_Ichigo1,
0x227a0711, 0xd089, 0x42aa, 0x84, 0x28, 0x52, 0xdd, 0x48, 0xa1, 0x41, 0x39);
DEFINE_GUIDマクロは、initguid.hをソースコードの先頭でインクルードした場合には、
const CLSID CLSID_Ichigo1 =
{ 0x227a0711, 0xd089, 0x42aa, { 0x84, 0x28, 0x52, 0xdd, 0x48, 0xa1, 0x41, 0x39 } };
extern const CLSID CLSID_Ichigo1;
#include <initguid.h>
どのソースコードからもinitguid.hをインクルードしなかった場合には、 CLSID_Ichigo1が存在しないため、リンクエラーになります。
文字列とBSTR
C++言語では文字列をchar(ANSI)やWCHAR(UNICODE)の配列として表しますが、 COMの多くのインターフェースでは、文字列をBSTRと呼ばれる長さつきの配列として扱います。 BSTRはCOMの管理するメモリ上で確保、解放されるUNICODEの文字列です。C++のUNICODE文字列は、SysAllocString()関数またはSysAllocStringLen()関数でBSTRに変換できます。 確保したBSTR文字列は、利用後にSysFreeString()関数で解放する必要があります。 これらのAPIは次の形をしています。
BSTR SysAllocString( const WCHAR* pstr );
BSTR SysAllocStringLen( const WCHAR* pstr, UINT len_in_wchar );
void SysFreeString( BSTR bstr );
COMのネイティブな文字列がUNICODEであるため、C++言語でも文字列をUNICODEで扱うと便利です。 UNICODE文字列はWCHARの配列で、ANSIの文字列とは次のメソッドで相互変換します。
| ANSI→UNICODE | MultiByteToWideChar |
| UNICODE→ANSI | WideCharToMultiByte |
int MultiByteToWideChar(
UINT codepage, DWORD dwFlags,
const char* pstr, int len_str,
WCHAR* pwstrbuf, int len_wstrbuf);
int WideCharToMultiByte(
UINT codepage, DWORD dwFlags,
const WCHAR* pwstr, int len_wstr,
char* pstrbuf, int len_strbuf,
const char* pdefault, BOOL* pdefault_flag
UNICODE文字列を直接ソースコードに書きたい場合は、文字列の先頭にLをつけます。
const WCHAR* wichigo = L"Ichigopack";
BSTR bstrichigo = SysAllocString( wichigo );
BSTRを必要とするメソッド呼び出しを実行
SysFreeString( bstrichigo );
COMのエラーコード
システムによって特別扱いされるAddRef()とRelease()を除き、 COMのメソッドはHRESULTと呼ばれるCOM全体で統一されたエラーコードを返します。 COMシステムでは、メソッド呼び出しインターフェースを介して毎回COMを呼び出します。 エラーコードを統一することにより、この呼び出し中にCOM部分でエラーが起こった場合でも、 メソッド呼び出しへの戻り値という形でエラーコードを返せることになります。HRESULTのコードのうちいくつかの例を以下に示します。
| エラーコード | SUCCEEDEDマクロは真か | 内容 |
| S_OK | Yes | 成功し、その戻り値はOK |
| S_FALSE | Yes | 成功し、その戻り値はFALSE |
| E_FAIL | No | 一般的な失敗 |
| E_NOTIMPL | No | 未実装 |
| E_OUTOFMEMORY | No | メモリ不足 |
そこで、成功か失敗かを判別するために、次の2つのマクロが用意されています。 hrはHRESULTコードとします。
| マクロ | 内容 |
| SUCCEEDED(hr) | 成功した場合に真、失敗した場合に偽 |
| FAILED(hr) | 失敗した場合に真、成功した場合に偽 |