OpenMPプログラミング - OpenMPを用いた並列実行
はじめに
このページ以降では、 OpenMPのコード例を示しながら、プログラミング方法について説明していきます。OpenMPをC/C++言語で使う場合でも、その実行ファイルは、 main関数が開始した時点では1つのプロセスと1つのスレッド(マスタースレッド)のみが存在し、 main関数を上から順に実行する実行ファイルになります。
マスタースレッドの実行中に#pragma omp で与えられるOpenMPの指示があると、 OpenMPに対応したコンパイラで生成された実行ファイルは、 マルチスレッドなど、OpenMPに対応した処理を実行します。
#pragma ompの対象範囲は、#pragmaが置かれた直後の1命令です。 複数の命令に対して適用したい場合には、適用したい範囲を{}で括ります。
並列実行とバリア
#pragma omp parallelは、OpenMPに並列実行を指示します。 omp parallelの対象範囲では、同じコードが並列に実行されます。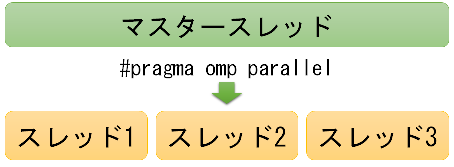 並列実行中にバリアが必要であれば#pragma omp barrierを置き、バリアを指示します。
並列実行中にバリアが必要であれば#pragma omp barrierを置き、バリアを指示します。
例えば、各スレッドでpという文字を出力するC++コードは次のようになります。
#include <iostream>
int main()
{
#pragma omp parallel
{
std::cout << "p";
#pragma omp barrier
}
return 0;
}
#pragma omp barrierは、その時点ですべてのスレッドが終了するまで待ちます。 #pragma omp parallelが終わる時点でバリア相当の処理が実行される保証はないようですので、 ここにバリアを置かないと、一部のスレッドが実行されないままmain関数が終了してしまう可能性があります。
4つのプロセッサコアで実行した場合の、実行結果の1例は次のようになります。
pppp
クリティカルセクション
先ほどの例では、複数のスレッドからstd::coutへの出力を行っていました。 これは、複数のスレッドから、同期をとらずに共有リソースにアクセスしていることになります。 このアクセス方法は間違っており、std::coutの実装によってはハングアップなども起こりえます。例として、各スレッドで出力する文字をpではなく、スレッド番号としたC++コードを用意しました。
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
std::cout << "ichiothread " << omp_get_thread_num() << std::endl;
#pragma omp barrier
}
return 0;
}
このコードは、ichiothread <スレッド番号><改行>がプロセッサコアの数だけ出力されることを期待しています。 しかしながら、4つのプロセッサコアで実行すると、例えば次の結果が得られます。
ichiothread 0ichiothread
ichiothread ichiothread 231
この問題を避けるためには、std::coutに対してクリティカルセクションを用意し、 std::coutへの出力をクリティカルセクションで保護する必要があります。 クリティカルセクションは次のように使います。
#pragma omp critical(クリティカルセクション名)
{
保護されるコード
}
先ほどの例において、std::coutをクリティカルセクションで保護すると、 次のソースコードになります。
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp critical(crit_cout)
{
std::cout << "ichigothread " << omp_get_thread_num() << std::endl;
}
#pragma omp barrier
}
return 0;
}
ichigothread 0
ichigothread 2
ichigothread 3
ichigothread 1
parallelのネスト
#pragma omp parallelを使うと、プロセッサコアの数だけスレッドが用意されます。 では、並列実行されたコード内で#pragma omp parallelを使うと、 OpenMPはどのように並列化するのでしょうか?実は、OpenMPは並列実行されたソースコードであることを検出し、 並列実行下で#pragma omp parallelが指示されると、 新たなスレッドを作成せずに、その対象範囲を1つのスレッドで実行します。 したがって、OpenMPに特別な指示をしない限り、 プロセッサコアの数を超えて同時実行されることは考えなくても良いでしょう。
例として、次のコードを考えます。このソースコードで用いるomp_get_num_threads()は、合計スレッド数を返すOpenMPの補助関数です。
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp critical(crit_cout)
{
std::cout << "ichigothread " << omp_get_thread_num()
<< ", total " << omp_get_num_threads() << std::endl;
}
#pragma omp barrier
}
return 0;
}
ichigothread 0, total 4
ichigothread 2, total 4
ichigothread 3, total 4
ichigothread 1, total 4
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp parallel
{
#pragma omp critical(crit_cout)
{
std::cout << "ichigothread " << omp_get_thread_num()
<< ", total " << omp_get_num_threads() << std::endl;
}
}
#pragma omp barrier
}
return 0;
}
ichigothread 0, total 1
ichigothread 0, total 1
ichigothread 0, total 1
ichigothread 0, total 1
ただし、ライブラリが同一のC/C++コンパイラを使っていない場合には、 余分なスレッドが生成されることがありますのでご注意ください。