並列実行中の1スレッド実行
並列化コードの途中で、一部のコードを1つのスレッドで実行したいことがあります。
例えばomp_get_thread_num()で0が返されたときだけ実行することもできますが、
OpenMPには次の表に示す専用の#pragma命令も用意されています。
| omp master | 対象範囲をスレッド番号0のスレッドで実行します。対象範囲の最後にバリアはありません。 |
| omp single | 対象範囲を1つのスレッドで実行します。スレッド番号は決まっていません。対象範囲の最後にバリアが挿入されます。 |
| omp single nowait | nowaitを追加することで、対象範囲の最後にバリアが挿入されないようにします。 |
例えば#pragma omp singleは次の図のような動作をします。
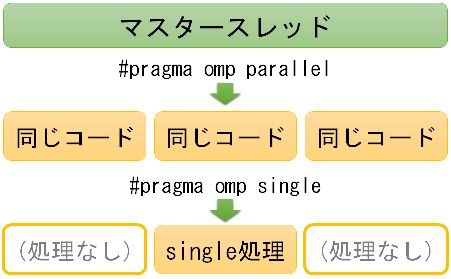
以下、各項目について例を示していきます。
omp master
omp masterで囲まれたコードは、スレッド番号0のスレッドで実行されます。
そのコード例は次のようになります。
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp critical(crit_cout)
{
std::cout << "parallel1: ichigothread "
<< omp_get_thread_num() << std::endl;
}
#pragma omp master
{
#pragma omp critical(crit_cout)
{
std::cout << "master: ichigothread "
<< omp_get_thread_num() << std::endl;
}
}
#pragma omp critical(crit_cout)
{
std::cout << "parallel2: ichigothread "
<< omp_get_thread_num() << std::endl;
}
#pragma omp barrier
}
return 0;
}
以下にその出力の1例を示します。
masterの最後にバリアはありませんので、
スレッド3でparallel1部分が完了する前に、スレッド0やスレッド2でparallel2部分が実行されたことがわかります。
parallel1: ichigothread 0
parallel1: ichigothread 2
master: ichigothread 0
parallel2: ichigothread 0
parallel2: ichigothread 2
parallel1: ichigothread 3
parallel1: ichigothread 1
parallel2: ichigothread 3
parallel2: ichigothread 1
omp single
omp singleで囲まれたコードは、1つのスレッドで実行されます。
そのコード例は次のようになります。
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp critical(crit_cout)
{
std::cout << "parallel1: ichigothread "
<< omp_get_thread_num() << std::endl;
}
#pragma omp single
{
#pragma omp critical(crit_cout)
{
std::cout << "single: ichigothread "
<< omp_get_thread_num() << std::endl;
}
}
#pragma omp critical(crit_cout)
{
std::cout << "parallel2: ichigothread "
<< omp_get_thread_num() << std::endl;
}
#pragma omp barrier
}
return 0;
}
以下にその出力の1例を示します。この例ではスレッド0で実行されていますが、別のスレッドで実行される可能性もあります。
singleの最後にはバリアが自動的に挿入されますので、
すべてのスレッドでparallel1部分が完了してから、parallel2部分が実行されたことがわかります。
parallel1: ichigothread 0
single: ichigothread 0
parallel1: ichigothread 1
parallel1: ichigothread 3
parallel1: ichigothread 2
parallel2: ichigothread 0
parallel2: ichigothread 2
parallel2: ichigothread 3
parallel2: ichigothread 1
omp single nowait
omp singleでは囲まれたコードの最後にバリアが挿入されるため、コードによっては実行効率が落ちます。
最後にnowaitと入れておくと、このバリアが自動的に挿入されることはなくなります。
(自分でバリアを置くことは可能です)
そのコード例は次のようになります。
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp critical(crit_cout)
{
std::cout << "parallel1: ichigothread "
<< omp_get_thread_num() << std::endl;
}
#pragma omp single nowait
{
#pragma omp critical(crit_cout)
{
std::cout << "single: ichigothread "
<< omp_get_thread_num() << std::endl;
}
}
#pragma omp critical(crit_cout)
{
std::cout << "parallel2: ichigothread "
<< omp_get_thread_num() << std::endl;
}
#pragma omp barrier
}
return 0;
}
以下にその出力の1例を示します。
バリアがなくなったことで、
スレッド1やスレッド3でparallel1部分が完了する前に、スレッド0でparallel2部分が実行されたことがわかります。
parallel1: ichigothread 0
single: ichigothread 0
parallel1: ichigothread 2
parallel2: ichigothread 0
parallel1: ichigothread 1
parallel1: ichigothread 3
parallel2: ichigothread 2
parallel2: ichigothread 3
parallel2: ichigothread 1
関連ページ
OpenMPの解説 目次
前の項目: OpenMPを用いた並列実行
次の項目: for文の並列実行