OpenMPプログラミング - for文の並列実行
for文の分割実行
同じことを繰り返し処理するfor文は、並列実行に向いています。 OpenMPでは#pragma omp parallelがあると同じコードが並列に実行されますが、 スレッドごとにループの区間を切り替えれば、繰り返し処理を複数のスレッドで分担できます。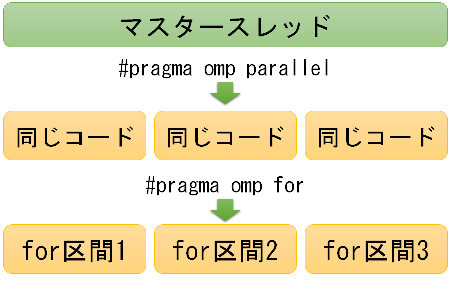 例として、次の6回のループを実行するソースコードを考えます。
例として、次の6回のループを実行するソースコードを考えます。
#include <iostream>
#include <omp.h>
int main()
{
{
for ( int ichigoloop = 0; ichigoloop < 6; ichigoloop++ ) {
std::cout << "ichigoloop " << ichigoloop
<< " thread " << omp_get_thread_num() << std::endl;
}
}
return 0;
}
ichigoloop 0 thread 0
ichigoloop 1 thread 0
ichigoloop 2 thread 0
ichigoloop 3 thread 0
ichigoloop 4 thread 0
ichigoloop 5 thread 0
このソースコードは、6回のループをスレッドに配分することで並列実行できます。 スレッド番号はomp_get_thread_num()、全スレッド数はomp_get_num_threads()で取得できますから、 ソースコードを次のように書き換えれば、6回のループは並列に実行できます。
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
int l_begin = omp_get_thread_num() * 6 / omp_get_num_threads();
int l_end = (omp_get_thread_num()+1) * 6 / omp_get_num_threads();
for ( int ichigoloop = l_begin; ichigoloop < l_end; ichigoloop++ ) {
#pragma omp critical(crit_cout)
{
std::cout << "ichigoloop " << ichigoloop
<< " thread " << omp_get_thread_num() << std::endl;
}
}
#pragma omp barrier
}
return 0;
}
ichigoloop 0 thread 0
ichigoloop 1 thread 1
ichigoloop 3 thread 2
ichigoloop 4 thread 3
ichigoloop 5 thread 3
ichigoloop 2 thread 1
OpenMPによるforループのサポート
ループを手作業でスレッドに配分しなくても並列化できるように、 OpenMPは#pragma omp forを提供しています。#pragma omp forは、並列実行中の範囲に置かれた場合にのみ、 直後にあるforループを各スレッドに配分する機能を持ちます。 omp_get_num_threads()が1を返す場合は、1つのスレッドで実行します。 #pragma omp forが新しいスレッドを作ることはありませんので、 並列実行したい場合は#pragma omp parallelが有効な範囲に#pragma omp forを置きます。
#pragma omp forを用いて先ほどのソースコードを書き換えると、次のようになります。
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp for
for ( int ichigoloop = 0; ichigoloop < 6; ichigoloop++ ) {
#pragma omp critical(crit_cout)
{
std::cout << "ichigoloop " << ichigoloop
<< " thread " << omp_get_thread_num() << std::endl;
}
}
#pragma omp barrier
}
return 0;
}
ichigoloop 0 thread 0
ichigoloop 1 thread 0
ichigoloop 4 thread 2
ichigoloop 5 thread 3
ichigoloop 2 thread 1
ichigoloop 3 thread 1
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp for
for ( int ichigoloop = 0; ichigoloop < 6; ichigoloop++ ) {
std::cout << "ichigoloop " << ichigoloop
<< " thread " << omp_get_thread_num() << std::endl;
}
#pragma omp barrier
}
return 0;
}
ichigoloop 0ichigoloop 2ichigoloop 4 thread thread ichigoloop 25
1 thread 3
thread 0ichigoloop 3 thread 1
ichigoloop 1 thread 0
forに対するバリアとnowait
#pragma omp forを使うと、forが終わる時点にバリアが自動的に挿入されます。 例として、次のコードを考えます。#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp for
for ( int ichigoloop = 0; ichigoloop < 6; ichigoloop++ ) {
#pragma omp critical(crit_cout)
{
std::cout << "ichigoloop " << ichigoloop
<< " thread " << omp_get_thread_num() << std::endl;
}
}
#pragma omp critical(crit_cout)
{
std::cout << "ichigothread " << omp_get_thread_num() << std::endl;
}
#pragma omp barrier
}
return 0;
}
ichigoloop 0 thread 0
ichigoloop 1 thread 0
ichigoloop 4 thread 2
ichigoloop 5 thread 3
ichigoloop 2 thread 1
ichigoloop 3 thread 1
ichigothread 1
ichigothread 2
ichigothread 0
ichigothread 3
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp for nowait
for ( int ichigoloop = 0; ichigoloop < 6; ichigoloop++ ) {
#pragma omp critical(crit_cout)
{
std::cout << "ichigoloop " << ichigoloop
<< " thread " << omp_get_thread_num() << std::endl;
}
}
#pragma omp critical(crit_cout)
{
std::cout << "ichigothread " << omp_get_thread_num() << std::endl;
}
#pragma omp barrier
}
return 0;
}
ichigoloop 0 thread 0
ichigoloop 1 thread 0
ichigothread 0
ichigoloop 4 thread 2
ichigoloop 5 thread 3
ichigoloop 2 thread 1
ichigoloop 3 thread 1
ichigothread 1
ichigothread 3
ichigothread 2
for文の実行順序制御
#pragma omp forを使うと、対象とするfor文は任意の順序で実行されます。 例えば次のコードを考えてみます。#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp for nowait
for ( int ichigoloop = 0; ichigoloop < 6; ichigoloop++ ) {
#pragma omp critical(crit_cout)
{
std::cout << "ichigoloop " << ichigoloop << " thread " << omp_get_thread_num() << std::endl;
}
}
#pragma omp barrier
}
return 0;
}
ichigoloop 0 thread 0
ichigoloop 4 thread 2
ichigoloop 2 thread 1
ichigoloop 1 thread 0
ichigoloop 3 thread 1
ichigoloop 5 thread 3
#pragma omp for orderedと#pragma omp orderedは、for文の実行順序を制御する機能を提供します。 この2つの#pragmaは、必ずセットで使います。
#pragma omp for orderedは、for文の直前に置きます。 この#pragmaは、for文の中に順序通り実行すべき部分が存在することを指示します。
#pragma omp orderedは、#pragma omp for orderedの対象となるfor文の中に置きます。 この#pragmaの対象領域は、for文のループ順序の通りに実行されます。
先のソースコードを、この2つの#pragmaを使って書き換えた例を示します。
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp for nowait ordered
for ( int ichigoloop = 0; ichigoloop < 6; ichigoloop++ ) {
#pragma omp ordered
{
#pragma omp critical(crit_cout)
{
std::cout << "ichigoloop " << ichigoloop << " thread " << omp_get_thread_num() << std::endl;
}
}
}
#pragma omp barrier
}
return 0;
}
ichigoloop 0 thread 0
ichigoloop 1 thread 0
ichigoloop 2 thread 1
ichigoloop 3 thread 1
ichigoloop 4 thread 2
ichigoloop 5 thread 3
#include <iostream>
#include <omp.h>
int main()
{
#pragma omp parallel
{
#pragma omp for nowait ordered
for ( int ichigoloop = 0; ichigoloop < 6; ichigoloop++ ) {
//#pragma omp ordered
#pragma omp critical(crit_cout)
{
std::cout << "ichigoloop " << ichigoloop << " thread " << omp_get_thread_num() << std::endl;
}
}
#pragma omp barrier
}
return 0;
}
ichigoloop 0 thread 0
ichigoloop 1 thread 0
ichigoloop 2 thread 1
ichigoloop 5 thread 3
ichigoloop 4 thread 2
ichigoloop 3 thread 1